







对于刚刚调优的读者,Spark是一个开源集群计算框架,最初是由加州大学伯克利分校(U.C. Berkeley) AMPLab的Matei Zaharia在2009年开发的,后来开源并捐赠给了Apache基金会。创建Spark的部分动机是,MapReduce只允许对数据进行一次遍历,而机器学习(ML)和绘图算法通常需要执行多次遍历。
Spark被标榜为“用于大规模数据处理的快速通用引擎”,其口号是“闪电般快速的集群计算”。“在大数据的世界里,Spark是否吸引了关注和投资因为它在Hadoop中提供了一个强大的内存数据处理组件,可以处理实时和批处理事件。除了Databricks, Spark还受到IBM、微软、亚马逊、华为和雅虎等公司的青睐。
Spark包括用于分布式机器学习的MLlib和用于分布式图形计算的GraphX。
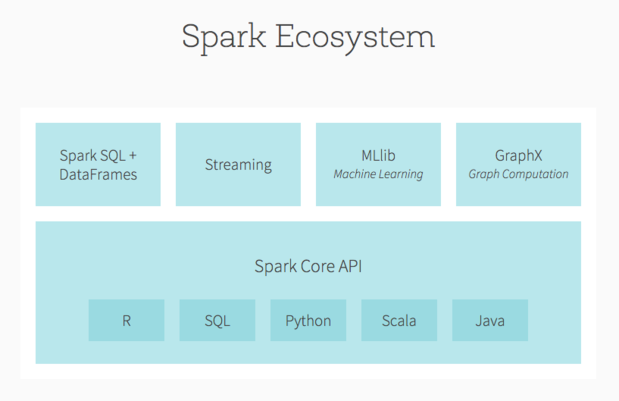
Spark核心支持R、SQL、Python、Scala和Java中的api。其他Spark模块包括Spark SQL和DataFrames;流媒体;用于机器学习的MLlib;GraphX用于图形计算。
本文对MLlib特别感兴趣。它包括广泛的ML和统计算法,都是为基于分布式内存的Spark体系结构量身定制的。MLlib实现了统计汇总、相关性、抽样、假设检验、分类和回归、协同过滤、聚类分析、降维、特征提取和转换函数以及优化算法。换句话说,对于数据科学家来说,这是一个相当完整的包。