






为了备份数据库,您需要知道如何交付, but you also need to know which of the more than 13 types of database designs it employs. Here we’ll cover four of them—relational, key-value, document, and wide column—that generate a lot of backup questions.
了解这些模型将有助于备份团队与数据库管理员建立关系和信任水平,这将有助于双方。
四种数据库类型
Relational
A relational-database management system (RDBMS) is a series of tables with a defined schema, or layout, with records in rows of one or more attributes, or values. There are relationships between the tables, which is why it is called a relational database, and why backups generally have to back up and restore everything. Examples of RDMBSs include Oracle, SQL Server, DB2, MySQL, and PostgreSQL
核心价值
一个键值数据库是许多不仅具有单个架构的SQL(NOSQL)数据库之一,该数据库由键和值组成,如果您知道键,则可以查找值。示例包括Redis和DynamoDB。
文档
文档数据库是专门为存储文档而设计的NOSQL DBMS。记录不需要符合任何统一标准,并且可以存储非常不同的数据。JSON通常用于将文档存储在这样的数据库中。MongoDB很容易成为仅支持文档模型的最受欢迎的数据库。
宽列
Wide-column databases are another schema-free NoSQL DBMS that can store very large numbers of columns of data, without a preschema. Column names and keys can be defined throughout the database. Cassandra is the best known database of this type.
Most admins are most familiar with backing up RDMBSs, which typically consist of daily database dumps of some sort, followed by hourly or continuous backup of the transaction logs. This allows you to restore the database to any point in time using the latest backup followed by replaying the transaction logs, which will recreate the transactions that occurred since the last backup. Keeping all of these backups on disk and accessible to the database in question makes restores much quicker.
核心价值databases are much simpler to back up because unlike RDMBs, there are no relationships between tables that prevent you from doing table-level backups versus backing up the whole database. Backups can therefore be done at the table level at any time using either a full or incremental dump.
另一方面,备份文档或宽列数据库可能非常复杂。这是因为它们通常以多节点配置运行,每个节点上的一部分数据库,而无需一个步骤备份整个数据库。但是,真正令人困惑的是,备份人是这些数据库使用的一致性模型。让我们看一下这些模型。
三个一致性模型
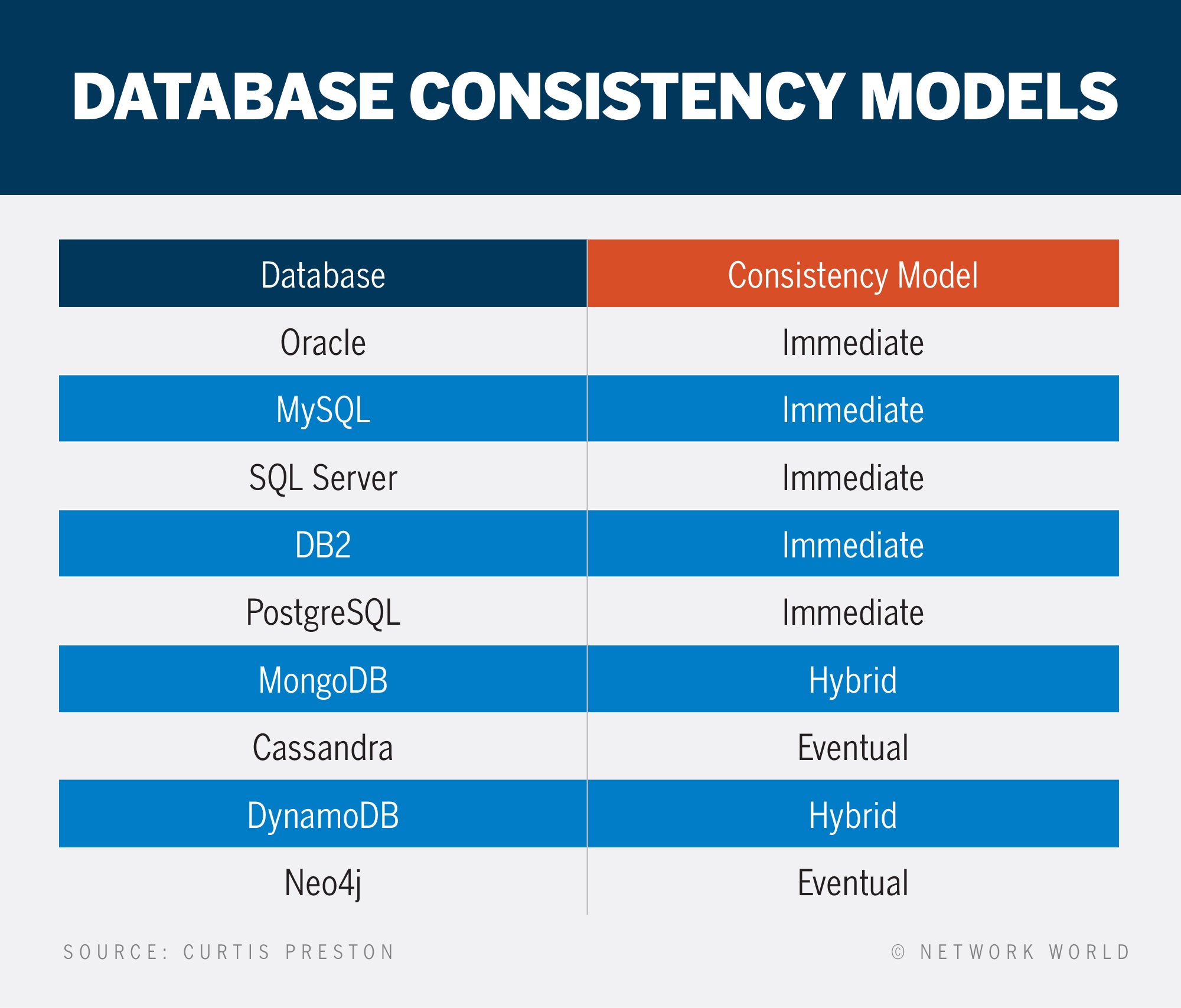
对于所有数据库的所有查看者,插入或更新的数据库数据的视图保持一致(或不),并且该一致性模型在两种截然不同的方法中保持一致(或不保持一致),并且该一致性模型可能会影响您对该数据库的备份和恢复的看法。考虑新记录插入后立即发生的事情。所有用户都会立即看到该记录是否插入?该问题的答案决定了数据库是否支持立即的一致性,最终的一致性或两者的混合体。
直接的一致性
直接的一致性,也称为强大的一致性,可确保所有用户在何处或如何查看数据的何处或如何看待相同的数据。大多数RDMS都遵循此模型。备份立即一致的数据库很容易,因为您可以通过任何支持的方法在任何时候对其进行备份,并且您将始终获得数据库的一致视图。
最终的一致性
The term eventual consistency comes from the idea that, provided no changes are made to the entity in question, all reads of that entity will return the same value—eventually. A great example of eventual consistency is the域名系统(DNS)。DNS更改可能需要几分钟到几个小时才能在世界上所有DNS服务器中传播,但最终的更改将导致这种变化,所有DNS服务器都将返回相同的值。这就是为什么备份最终一致的数据库比立即稳定性备份的数据库更复杂的原因。
混合一致性
混合一致性is often used in NoSQL databases that supports eventually consistent writes but allows you to specify on a per-API-call basis the level of consistency you need on a read. Backup processes can use this feature to specify they want fully consistent data.
The consistency model can affect your data protection method because you need to be sure you are backing up or have the ability to restore consistent data. If, for example, you backed up an out-of-date database node in a multi-node database like MongoDB or Cassandra, your backup would be out of date. And if one node had part of the data, and another node had another part of the data from a different point-in-time, you would not get a consistent backup of all data by backing them both up at the same time. You would have what is called referential integrity issues between the two nodes if you restored them to two different points in time. Here’s which databases support which consistency models:
 罗布·舒尔茨(Rob Schultz)
罗布·舒尔茨(Rob Schultz)
遵循三个步骤
要成功备份数据库,首先知道它的交付方式 - 您控制的硬件或VMS,其他人的硬件作为服务或仅插入,更新或删除记录的无服务器。
接下来,知道您正在处理哪种数据库,这也将决定其备份的方式。如果它是Oracle或SQL Server(例如Oracle或SQL Server)的流行RDBM,则很可能会使用您喜欢的备份产品中的备份代理。这将使您可以将备份数据直接发送到用于备份的任何存储或云系统。如果这是此处讨论的其他三个数据库模型之一,则您很可能必须使用转储和扫描方法,在该方法中,您使用产品的备份工具在磁盘上创建备份,然后在备份系统中扫描。垃圾场可能比备用代理设置更为复杂,但具有更大的灵活性。
The third and biggest challenge comes if you have a multi-node database using the eventually consistent model. Do not listen to anyone who tells you that the database doesn’t need backups. While they can survive many things, like node failures, these databases are still susceptible to human error and cyberattacks. Research the product in question and find out how to get a backup of either the entire database or each table in that database. With such node-level resiliency, you will most likely be restoring things at a table level.
Learn as much as you can about the databases in your environment, whether they’re in your data center, running in VMs in the cloud, or simply provided to you as a service. Then learn what type of database and consistency model they use and use that knowledge to talk to the DBAs and be their friends. Then find the option that prioritizes the kind of restores that database is likely to need.